

## [Highly Accurate Dichotomous Image Segmentation (ECCV 2022)](https://arxiv.org/pdf/2203.03041.pdf)
[Xuebin Qin](https://xuebinqin.github.io/), [Hang Dai](https://scholar.google.co.uk/citations?user=6yvjpQQAAAAJ&hl=en), [Xiaobin Hu](https://scholar.google.de/citations?user=3lMuodUAAAAJ&hl=en), [Deng-Ping Fan*](https://dengpingfan.github.io/), [Ling Shao](https://scholar.google.com/citations?user=z84rLjoAAAAJ&hl=en), [Luc Van Gool](https://scholar.google.com/citations?user=TwMib_QAAAAJ&hl=en).
## This is the official repo for our newly formulated DIS task:
[**Project Page**](https://xuebinqin.github.io/dis/index.html), [**Arxiv**](https://arxiv.org/pdf/2203.03041.pdf).
# PLEASE STAY TUNED FOR OUR DIS V2.0 (Jul. 30th, 2022)

# Updates !!!
** (2022-Jul.-30)** Thank [**AK391**](https://github.com/AK391) for the implementaiton of a Web Demo: Integrated into [Huggingface Spaces 🤗](https://huggingface.co/spaces) using [Gradio](https://github.com/gradio-app/gradio). Try out the Web Demo [](https://huggingface.co/spaces/doevent/dis-background-removal).
Notes for official DIS group: Currently, the released DIS deep model is the academic version that was trained with DIS V1.0, which includes very few animal, human, cars, etc. So it may not work well on these targets. We will release another version for general use and test. In addition, our DIS V2.0 will cover more categories with extremely well-annotated samples. Please stay tuned.
** (2022-Jul.-17)** Our paper, code and dataset are now officially released!!! Please check our project page for more details: [**Project Page**](https://xuebinqin.github.io/dis/index.html).
** (2022-Jul.-5)** Our DIS work is now accepted by ECCV 2022, the code and dataset will be released before July 17th, 2022. Please be aware of our updates.
## 1. Our Dichotomous Image Segmentation (DIS) Dataset
### 1.1 [DIS dataset V1.0: DIS5K](https://xuebinqin.github.io/dis/index.html)
### Download: [Google Drive](https://drive.google.com/file/d/1jOC2zK0GowBvEt03B7dGugCRDVAoeIqq/view?usp=sharing) or [Baidu Pan 提取码:rtgw](https://pan.baidu.com/s/1y6CQJYledfYyEO0C_Gejpw?pwd=rtgw)

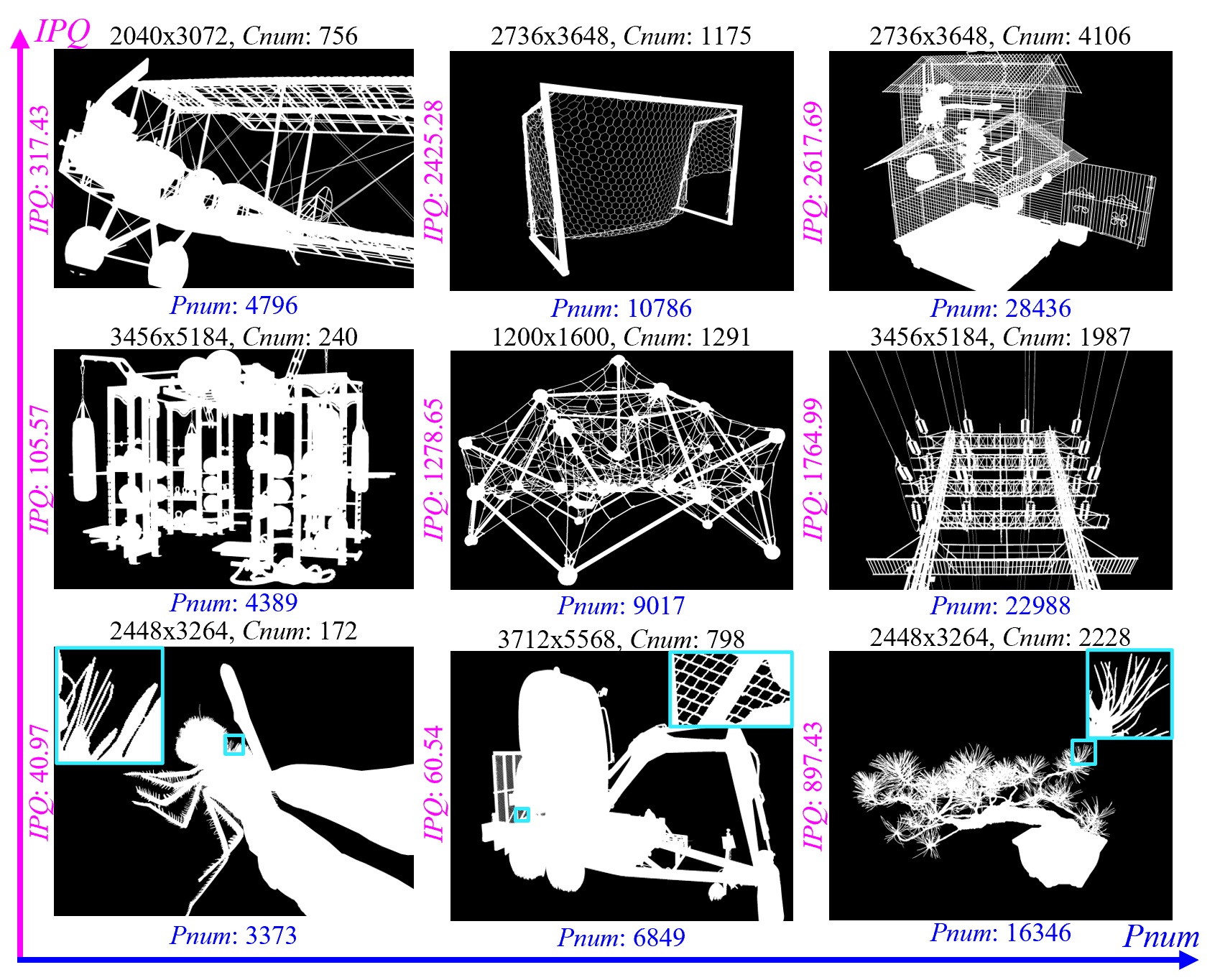

### 1.2 [DIS dataset V2.0](https://github.com/xuebinqin/DIS)
Although our DIS5K V1.0 includes samples from more than 200 categories, many categories, such as human, animals, cars and so on, in real world are not included. [So the current version (v1.0) of our dataset may limit the robustness of the trained models.]() To build the comprehensive and large-scale highly accurate dichotomous image segmentation dataset, we are building our DIS dataset V2.0. The V2.0 will be released soon. Please stay tuned.
Samples from DIS dataset V2.0.

## 2. APPLICATIONS of Our DIS5K Dataset
### 3D Modeling

### Image Editing

### Art Design Materials

### Still Image Animation

### AR

### 3D Rendering

## 3. Architecture of Our IS-Net

## 4. Human Correction Efforts (HCE)

## 5. Experimental Results
### Predicted Maps, [(Google Drive)](https://drive.google.com/file/d/1FMtDLFrL6xVc41eKlLnuZWMBAErnKv0Y/view?usp=sharing), [(Baidu Pan 提取码:ph1d)](https://pan.baidu.com/s/1WUk2RYYpii2xzrvLna9Fsg?pwd=ph1d), of Our IS-Net and Other SOTAs
### Qualitative Comparisons Against SOTAs

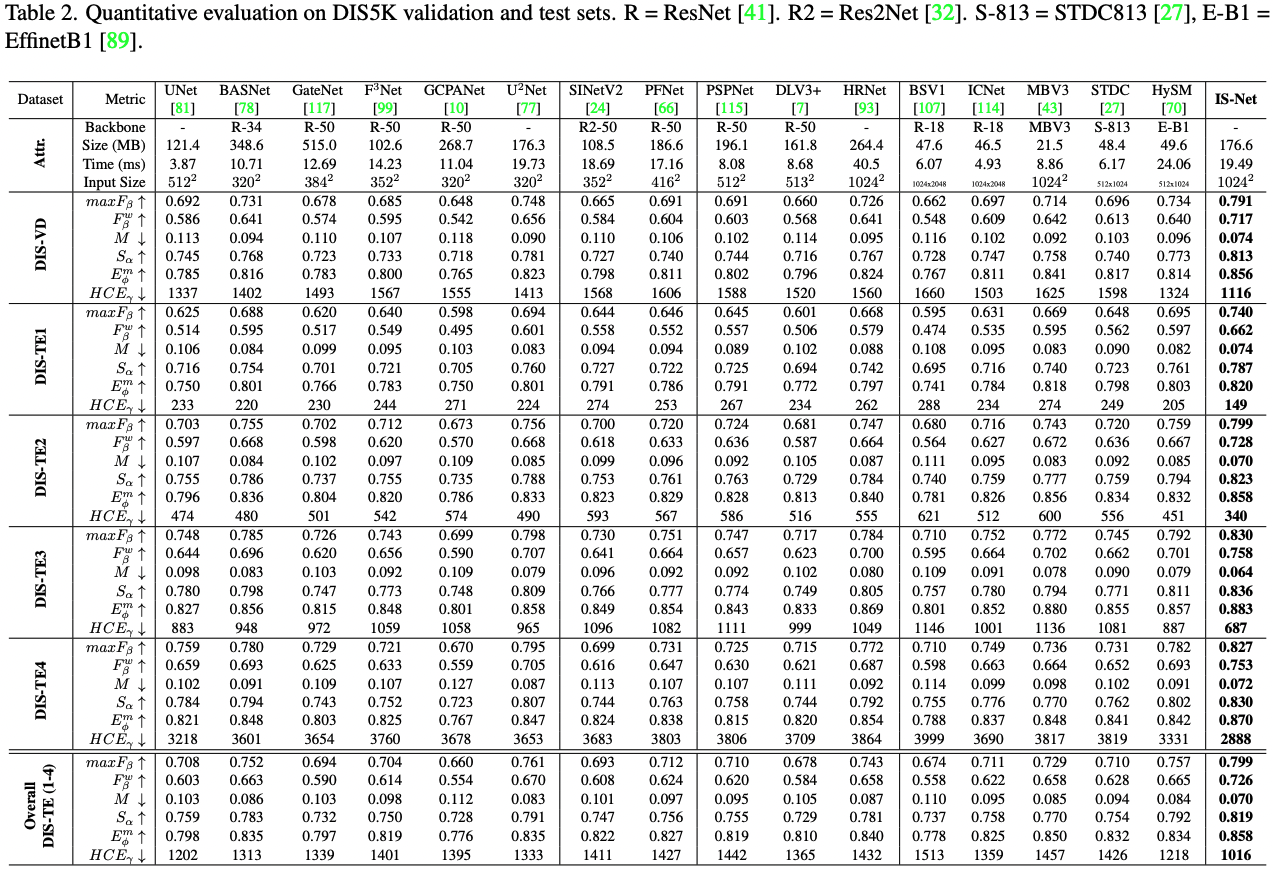
### Quantitative Comparisons Against SOTAs
## 6. Run Our Code
### (1) Clone this repo
```
git clone https://github.com/xuebinqin/DIS.git
```
### (2) Configuring the environment: go to the ```DIS/ISNet``` folder and run
```
conda env create -f pytorch18.yml
```
Or you can check the ```requirements.txt``` to configure the dependancies.
### (3) activate the conda environment by
```
conda activate pytorch18
```
### (4) Train:
(a) Open ```train_valid_inference_main.py```, set the path of your to-be-inferenced ```train_datasets``` and ```valid_datasets```, e.g., ```valid_datasets=[dataset_vd]```
(b) Set the ```hypar["mode"]``` to ```"train"```
(c) Create a new folder ```your_model_weights``` in the directory ```saved_models``` and set it as the ```hypar["model_path"] ="../saved_models/your_model_weights"``` and make sure ```hypar["valid_out_dir"]```(line 668) is set to ```""```, otherwise the prediction maps of the validation stage will be saved to that directory, which will slow the training speed down
(d) Run
```
python train_valid_inference_main.py
```
### (5) Inference
Download the pre-trained weights (for fair academic comparisons) ```isnet.pth``` from [(Google Drive)](https://drive.google.com/file/d/1KyMpRjewZdyYfxHPYcd-ZbanIXtin0Sn/view?usp=sharing) or [(Baidu Pan 提取码:xbfk)](https://pan.baidu.com/s/1-X2WutiBkWPt-oakuvZ10w?pwd=xbfk) or the optimized model weights ```isnet-general-use.pth``` (for general use) from [(Google Drive)](https://drive.google.com/file/d/1nV57qKuy--d5u1yvkng9aXW1KS4sOpOi/view?usp=sharing) or [(Baidu Pan 提取码:6jh2)](https://pan.baidu.com/s/111MqmwnUc8Z4Wsq2Pc4bhQ?pwd=6jh2), and store them in ```saved_models/IS-Net```
## I. Simple inference code for your own dataset without ground truth:
(a) Open ```\ISNet\inference.py``` and configure your input and output directories
(b) Run
```
python inference.py
```
## II. Inference for dataset with/without ground truth
(a) Open ```train_valid_inference_main.py```, set the path of your to-be-inferenced ```valid_datasets```, e.g., ```valid_datasets=[dataset_te1, dataset_te2, dataset_te3, dataset_te4]```
(b) Set the ```hypar["mode"]``` to ```"valid"```
(c) Set the output directory of your predicted maps, e.g., ```hypar["valid_out_dir"] = "../DIS5K-Results-test"```
(d) Run
```
python train_valid_inference_main.py
```
### (5) Use of our Human Correction Efforts(HCE) metric
Set the ground truth directory ```gt_root``` and the prediction directory ```pred_root```. To reduce the time costs for computing HCE, the skeletion of the DIS5K dataset can be pre-computed and stored in ```gt_ske_root```. If ```gt_ske_root=""```, the HCE code will compute the skeleton online which usually takes a lot for time for large size ground truth. Then, run ```python hce_metric_main.py```. Other metrics are evaluated based on the [SOCToolbox](https://github.com/mczhuge/SOCToolbox).
## 7. Term of Use
Our code and evaluation metric use Apache License 2.0. The Terms of use for our DIS5K dataset is provided as [DIS5K-Dataset-Terms-of-Use.pdf](DIS5K-Dataset-Terms-of-Use.pdf).
## Acknowledgements
We would like to thank Dr. [Ibrahim Almakky](https://scholar.google.co.uk/citations?user=T9MTcK0AAAAJ&hl=en) for his helps in implementing the dataloader cache machanism of loading large-size training samples and Jiayi Zhu for his efforts in re-organizing our code and dataset.
## Citation
```
@InProceedings{qin2022,
author={Xuebin Qin and Hang Dai and Xiaobin Hu and Deng-Ping Fan and Ling Shao and Luc Van Gool},
title={Highly Accurate Dichotomous Image Segmentation},
booktitle={ECCV},
year={2022}
}
```
## Our Previous Works: [U2-Net](https://github.com/xuebinqin/U-2-Net), [BASNet](https://github.com/xuebinqin/BASNet).
```
@InProceedings{Qin_2020_PR,
title = {U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection},
author = {Qin, Xuebin and Zhang, Zichen and Huang, Chenyang and Dehghan, Masood and Zaiane, Osmar and Jagersand, Martin},
journal = {Pattern Recognition},
volume = {106},
pages = {107404},
year = {2020}
}
@InProceedings{Qin_2019_CVPR,
author = {Qin, Xuebin and Zhang, Zichen and Huang, Chenyang and Gao, Chao and Dehghan, Masood and Jagersand, Martin},
title = {BASNet: Boundary-Aware Salient Object Detection},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2019}
}
@article{qin2021boundary,
title={Boundary-aware segmentation network for mobile and web applications},
author={Qin, Xuebin and Fan, Deng-Ping and Huang, Chenyang and Diagne, Cyril and Zhang, Zichen and Sant'Anna, Adri{\`a} Cabeza and Suarez, Albert and Jagersand, Martin and Shao, Ling},
journal={arXiv preprint arXiv:2101.04704},
year={2021}
}